


SCREAMING FROG SEO SPIDER – VERSION 2.30

Программа для сбора SEO данных по сайту на мой взгляд одна из лучших.
[HIDE-THANKS]
Скачать можно по ссылке ниже:
https://cloud.mail.ru/public/69c8a57711c6%2FScreamingFrogSEOSpider-2.11.exe
Keys до конца апреля 2015 года :
Username : S0mE0nE
Key : BD3009AEC0-1429713475-1A31CCCAE2
____________________________________
Username : V4lD3s7
Key : 91BFA7E5E6-1429713511-CAF5567285
____________________________________
Username : B3sTBlacKhaT
Key : 1CC376B5CB-1429713548-C475587EF1
____________________________________
[/HIDE-THANKS]
Программа для сбора SEO данных по сайту на мой взгляд одна из лучших.
[HIDE-THANKS]
Скачать можно по ссылке ниже:
https://cloud.mail.ru/public/69c8a57711c6%2FScreamingFrogSEOSpider-2.11.exe
Keys до конца апреля 2015 года :
Username : S0mE0nE
Key : BD3009AEC0-1429713475-1A31CCCAE2
____________________________________
Username : V4lD3s7
Key : 91BFA7E5E6-1429713511-CAF5567285
____________________________________
Username : B3sTBlacKhaT
Key : 1CC376B5CB-1429713548-C475587EF1
____________________________________
[/HIDE-THANKS]
I am delighted to announce version 2.20 of the Screaming Frog SEO spider.

We have been busy behind the scenes developing some very cool new features which we hope everyone will enjoy! As always, thank you to everyone for their fantastic feedback and suggestions, we still have plenty more to come. Version 2.20 now includes the following –
Redirect Chains Report
There is a new ‘reports’ menu in the top level navigation of the UI, which contains the redirect chains report. This report essentially maps out chains of redirects, the number of hops along the way and will identify the source, as well as if there is a loop. This is really useful as the latency for users can be longer with a chain, a little extra PageRank can dissipate in each hop and a large chain of 301s can be seen as a 404 by Google (Matt discussed this in a Google Webmaster Help video here).
Another very cool part of the redirect chain report is how it works for site migrations alongside the new ‘Always follow redirects‘ option (in the ‘advanced tab’ of the spider configuration). Now when you tick this box, the SEO spider will continue to crawl redirects even in list mode and ignore crawl depth.
Previously the SEO Spider would only crawl the first redirect and report the redirect URL target under the ‘Response Codes’ tab. However, as list mode is essentially working at a crawl depth of ‘0’, you wouldn’t see the status of the redirect target which, particularly on migrations is required when a large number of URLs are changed. Potentially a URL could 301, then 301 again and then 404. To find this previously, you had to upload each set of target URLs each time to analyse responses and the destination. Now, the SEO Spider will continue to crawl, until it has found the final target URL. For example, you can view redirect chains in a nice little report in list mode now.
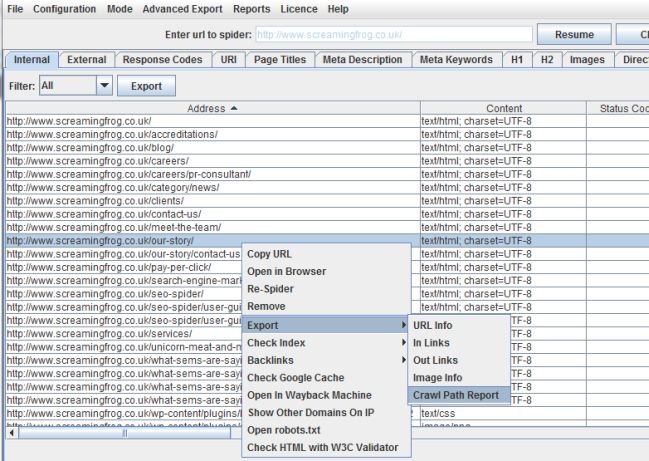
Crawl Path Report
Have you ever wanted to know how a URL was discovered? Obviously you can view ‘in links’ of a URL, but when there is a particularly deep page, or perhaps an infinite URLs issue caused by incorrect relative linking, it can be a pain to track down the originating source URL (Tip! – To find the source manually, sort URLs alphabetically and find the shortest URL in the sequence!). However, now on right click of a URL (under ‘export’), you can see how the spider discovered a URL and what crawl path it took from start to finish.
Respect noindex & Canonical
You now have the option to ‘respect’ noindex and canonical directives. If you tick this box under the advanced tab of the spider configuration, the SEO Spider will respect them. This means ‘noindex’ URLs will obviously still be crawled, but they will not appear in the interface (in any tab) and URLs which have been ‘canonicalised’ will also not appear either. This is useful when analysing duplicate page titles, or descriptions which have been fixed by using one of these directives above.
rel=“next” and rel=“prev”
The SEO Spider now collects these html link elements designed to indicate the relationship between URLs in a paginated series. rel=“next” and rel=“prev” can now be seen under the ‘directives’ tab.
Custom Filters Now Regex
Similar to our include, exclude and internal search function, the custom filters now support regex, rather than just query string. Oh and we have increased the number of filters from five to ten and included ‘occurrences’. So if you’re searching for an analytics UA ID or a particular phrase, the number of times it appears within the source code of a URL will be reported as well.
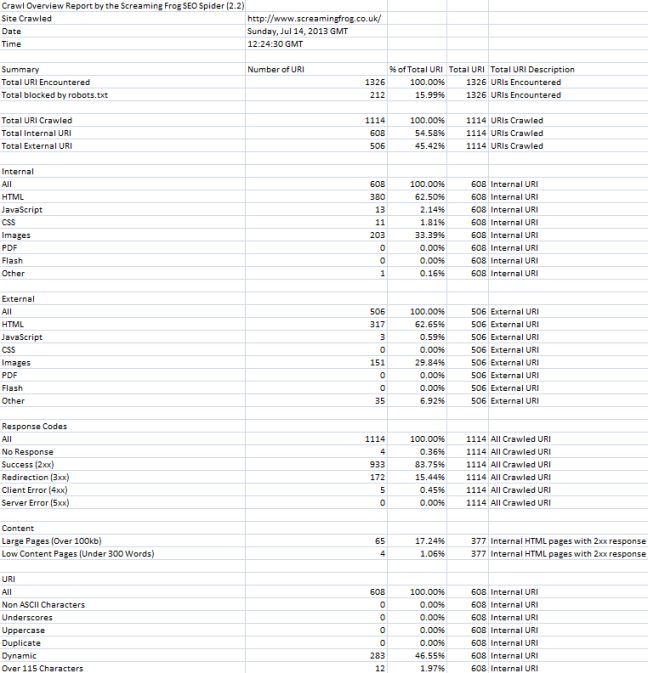
Crawl Overview Report
Under the new ‘reports’ menu discussed above, we have included a little ‘crawl overview report’. This does exactly what it says on the tin and provides an overview of the crawl, including total number of URLs encountered in the crawl, the total actually crawled, the content types, response codes etc with proportions. This will hopefully provide another quick easy way to analyse overall site health at a glance. Here’s a third of what the report looks like –
We have also changed the max page title length to 65 characters (although it seems now to be based on pixel image width), added a few more preset mobile user agents, fixed some bugs (such as large sitemaps being created over the 10Mb limit) and made other smaller tweaks along the way.
As always, we love any feedback and thank you again for all your support. Please do update your SEO Spider now to try out all the new features.
We have been busy behind the scenes developing some very cool new features which we hope everyone will enjoy! As always, thank you to everyone for their fantastic feedback and suggestions, we still have plenty more to come. Version 2.20 now includes the following –
Redirect Chains Report
There is a new ‘reports’ menu in the top level navigation of the UI, which contains the redirect chains report. This report essentially maps out chains of redirects, the number of hops along the way and will identify the source, as well as if there is a loop. This is really useful as the latency for users can be longer with a chain, a little extra PageRank can dissipate in each hop and a large chain of 301s can be seen as a 404 by Google (Matt discussed this in a Google Webmaster Help video here).
Another very cool part of the redirect chain report is how it works for site migrations alongside the new ‘Always follow redirects‘ option (in the ‘advanced tab’ of the spider configuration). Now when you tick this box, the SEO spider will continue to crawl redirects even in list mode and ignore crawl depth.
Previously the SEO Spider would only crawl the first redirect and report the redirect URL target under the ‘Response Codes’ tab. However, as list mode is essentially working at a crawl depth of ‘0’, you wouldn’t see the status of the redirect target which, particularly on migrations is required when a large number of URLs are changed. Potentially a URL could 301, then 301 again and then 404. To find this previously, you had to upload each set of target URLs each time to analyse responses and the destination. Now, the SEO Spider will continue to crawl, until it has found the final target URL. For example, you can view redirect chains in a nice little report in list mode now.
Crawl Path Report
Have you ever wanted to know how a URL was discovered? Obviously you can view ‘in links’ of a URL, but when there is a particularly deep page, or perhaps an infinite URLs issue caused by incorrect relative linking, it can be a pain to track down the originating source URL (Tip! – To find the source manually, sort URLs alphabetically and find the shortest URL in the sequence!). However, now on right click of a URL (under ‘export’), you can see how the spider discovered a URL and what crawl path it took from start to finish.
Respect noindex & Canonical
You now have the option to ‘respect’ noindex and canonical directives. If you tick this box under the advanced tab of the spider configuration, the SEO Spider will respect them. This means ‘noindex’ URLs will obviously still be crawled, but they will not appear in the interface (in any tab) and URLs which have been ‘canonicalised’ will also not appear either. This is useful when analysing duplicate page titles, or descriptions which have been fixed by using one of these directives above.
rel=“next” and rel=“prev”
The SEO Spider now collects these html link elements designed to indicate the relationship between URLs in a paginated series. rel=“next” and rel=“prev” can now be seen under the ‘directives’ tab.
Custom Filters Now Regex
Similar to our include, exclude and internal search function, the custom filters now support regex, rather than just query string. Oh and we have increased the number of filters from five to ten and included ‘occurrences’. So if you’re searching for an analytics UA ID or a particular phrase, the number of times it appears within the source code of a URL will be reported as well.
Crawl Overview Report
Under the new ‘reports’ menu discussed above, we have included a little ‘crawl overview report’. This does exactly what it says on the tin and provides an overview of the crawl, including total number of URLs encountered in the crawl, the total actually crawled, the content types, response codes etc with proportions. This will hopefully provide another quick easy way to analyse overall site health at a glance. Here’s a third of what the report looks like –
We have also changed the max page title length to 65 characters (although it seems now to be based on pixel image width), added a few more preset mobile user agents, fixed some bugs (such as large sitemaps being created over the 10Mb limit) and made other smaller tweaks along the way.
As always, we love any feedback and thank you again for all your support. Please do update your SEO Spider now to try out all the new features.
Спасибо говорим кнопкой:↓
 Мне нравится↓
Мне нравится↓
